近日,计算机视觉领域的顶级国际会议CVPR 2025论文录用结果揭晓,厦门大学多媒体可信感知与高效计算教育部重点实验室共有24篇论文被录用。
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)是计算机视觉领域的顶级国际会议,CCF A类会议。CVPR2025将于2025年6月11日至15日在美国田纳西州纳什维尔举办。CVPR 2025 共有13,008 份投稿,录用2878篇,录取率为 22.1%。
01
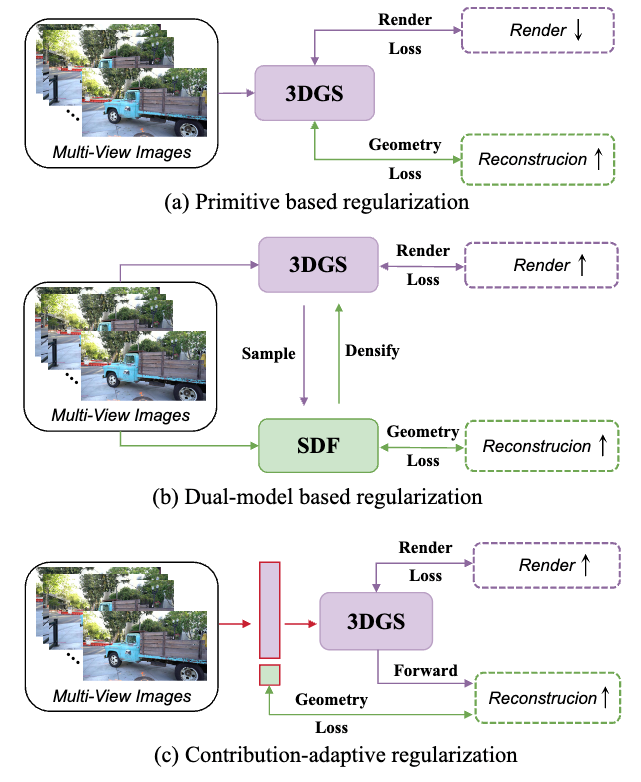
Evolving High-Quality Rendering and Reconstruction in a Unified Framework with Contribution-Adaptive Regularization
简介:本文提出了一种基于三维高斯泼溅 (3D Gaussian Splatting, 3DGS)的贡献自适应正则化的统一模型CarGS,用以实现同时进行的高质量渲染和表面重建。此外,本文还引入了一种几何引导的致密化策略,利用法线和符号距离场的线索进一步提升捕获高频细节的能力。本文的框架提升了渲染和几何重建两个任务的互助学习能力,同时其统一的结构无需像双模型方法那样使用单独的模型作用于不同任务,保证了高效性。广泛的实验表明,CarGS能够在保持实时速度和最小存储大小的同时,在渲染保真度和重建精度上实现SOTA的结果。
该论文的共同第一作者是厦门大学信息学院计算机系2024级博士研究生沈优和滴滴创新实验室研究员张志鹏,通讯作者是曹刘娟教授,由2023级博士生李新阳,2023级博士生曲延松,2024级博士研究生林煜、张声传副教授,曹刘娟教授共同合作完成。
02
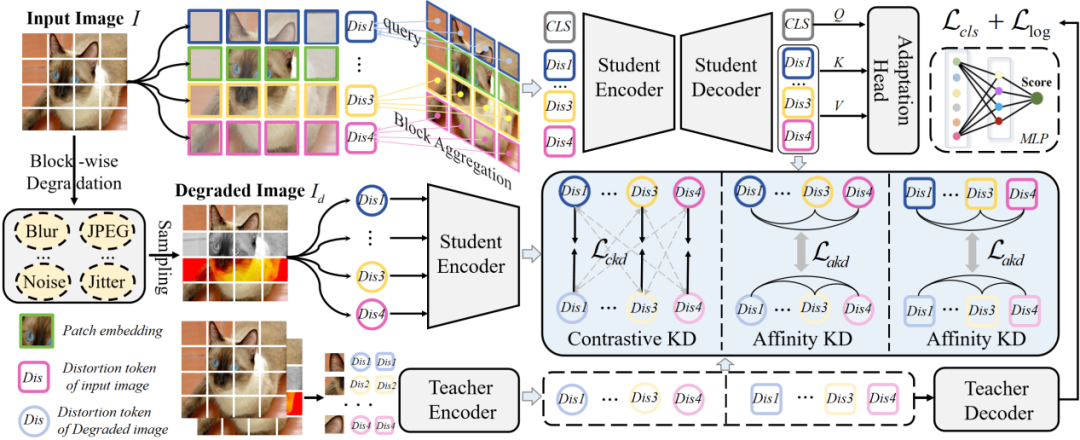
Distilling Spatially-Heterogeneous Distortion Perception for Blind Image Quality Assessment
简介:在盲图像质量评价(BIQA)领域,由于自然环境中失真类型的多样性,准确评估真实失真图像的质量是一个巨大的挑战。现有的最先进的IQA方法通过对整个图像施加一系列失真来建立全局失真先验,但这些方法难以有效处理具有空间变化失真的图像。为解决这个问题,本文提出一种新的IQA框架,利用知识蒸馏来感知空间异构失真,增强质量失真感知。具体而言,本文提出了一种基于分块的退化建模方法,对图像的不同空间块应用不同的失真,从而扩展了局部失真先验。在此基础上,本文设计了一个分块聚合和过滤模块,能够对图像中不同失真区域的质量信息进行细粒度关注。此外,为了在保持质量感知的同时增强不同区域失真的感知粒度,本文引入了对比知识蒸馏和亲和知识蒸馏策略,分别学习不同区域的失真判别能力和失真相关性。在多个标准IQA数据集上进行的实验证明了所提出方法的有效性。
该论文第一作者是厦门大学人工智能研究院2023级硕士生李旭东,通讯作者是曹刘娟教授,由张岩工程师、胡润泽副研究员(北京理工大学)、郑侠武副教授等共同合作完成。
03
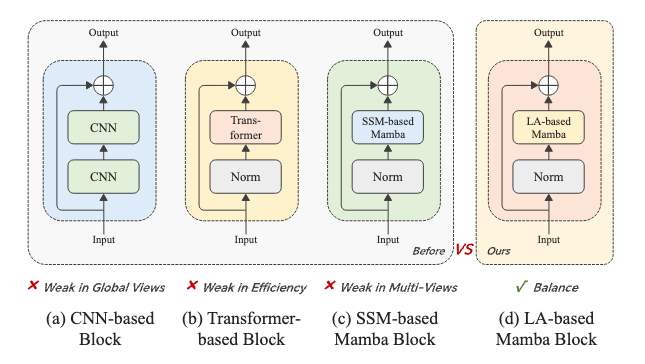
ACL: Activating Capability of Linear Attention for Image Restoration
简介:图像修复作为计算机视觉领域的核心课题,在深度学习驱动下已迈入全新阶段。当前基于CNN和Transformer的主流方法虽取得进展,但面临全局感受野受限与计算效率不足的双重挑战。针对这些问题,本研究创新性地提出基于ACL架构的模型:通过利用Mamba模型中状态空间模型(SSM)与线性注意力(linear attention)的表达同构性,采用线性注意力模块取代传统SSM作为编解码器核心,在保持全局感知能力的同时显著提升计算效率。此外,设计的多尺度空洞卷积局部增强模块为模型注入局部学习能力,能有效提取粗细粒度特征以优化局部细节重建。实验表明,该模型在去模糊、去雨等经典IR任务中均取得优异性能,且参数量与计算量(FLOPs)保持较低水平,可为移动端实时图像增强、安防监控画质优化等场景提供了更轻量高效的解决方案。
该论文第一作者为厦门大学信息学院2023级博士生谷雨斌,通讯作者是孙晓帅教授,由2024级硕士生孟媛、博士后纪家沂等共同合作完成。
04
Towards General Visual-Linguistic Face Forgery Detection
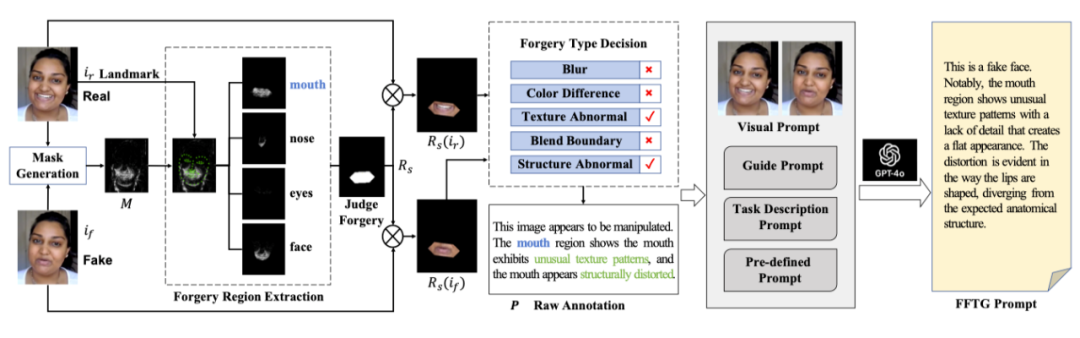
简介:本文针对面部伪造检测领域中文本注释的质量问题提出了创新性解决方案。随着面部伪造篡改技术的发展,现有的检测方法在泛化能力和可解释性方面面临挑战。本研究提出了一种新型注释方法 Face Forgery Text Generator (FFTG),通过利用伪造掩码进行初始区域和类型识别,结合全面的提示策略来减少多模态大型语言模型中的幻觉问题。FFTG生成的文本注释在识别伪造区域方面显著优于人工标注和直接的GPT标注,准确率提高了27%。基于这些高质量注释,通过微调CLIP和多模态LLM进行验证,实验结果表明本方法不仅能产生更准确的注释,还能提高模型在各种伪造检测基准上的性能。FFTG为多模态伪造检测提供了一种兼具泛化能力和可解释性的方法,为未来多模态取证任务的研究提供了全新的思路。
本文第一作者是厦门大学2021级博士生孙可,通讯作者是孙晓帅教授,由陈燊(腾讯优图)、姚太平(腾讯优图)、林嘉文教授(台湾清华大学)、2023级硕士生周子寅、博士后研究院纪家沂、孙晓帅教授(通讯作者)、纪荣嵘教授合作完成。
05
FlashSloth: Lightning Multimodal Large Language Models via Embedded Visual Compression
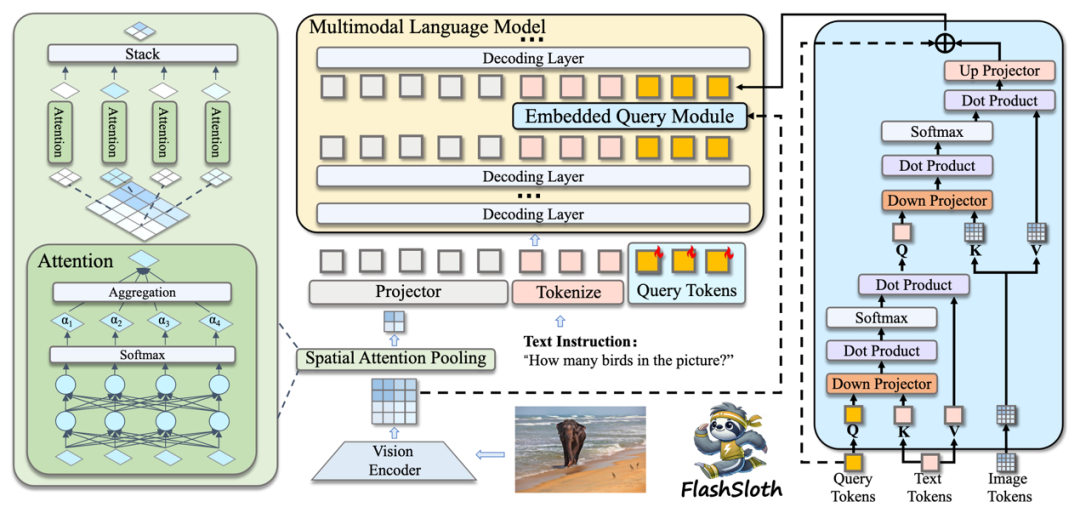
简介:现有多模态大语言模型(MLLM)在性能上有了显著提升,但在实际应用中往往存在响应缓慢和延迟大的问题。近期学术界和工业界都聚焦小型(tiny) MLLM ,但现有工作仍然受限于大量视觉标记的使用,未能达到实际模型加速和快响应的目的。本文提出了一种功能强大且高效的小型MLLM,称为 FlashSloth。FlashSloth在压缩冗余语义的同时,专注于提升视觉标记的描述能力。具体而言,FlashSloth 引入了嵌入式视觉压缩设计,通过空间注意力池化模块和嵌入式查询模块分别捕捉显著性的和与指令相关的图像信息,从而以更少的视觉标记实现卓越的多模态性能。广泛的实验表明,与 InternVL2、MiniCPM-V2 和 Qwen2-VL 等先进的小参数量MLLM相比,FlashSloth 能够显著提升训练与推理效率,响应时间可以压缩到0.01秒内,同时在多项视觉语言任务上保持高性能。
该论文第一作者为厦门大学信息学院2023级硕士生佟浡,通讯作者是周奕毅副教授,由2021级本科生赖博恺、2021级博士生罗根、沈云航(腾讯优图实验室)、李珂(腾讯优图实验室)、孙晓帅教授、纪荣嵘教授共同合作完成。
06
SVFR: A Unified Framework for Generalized Video Face Restoration
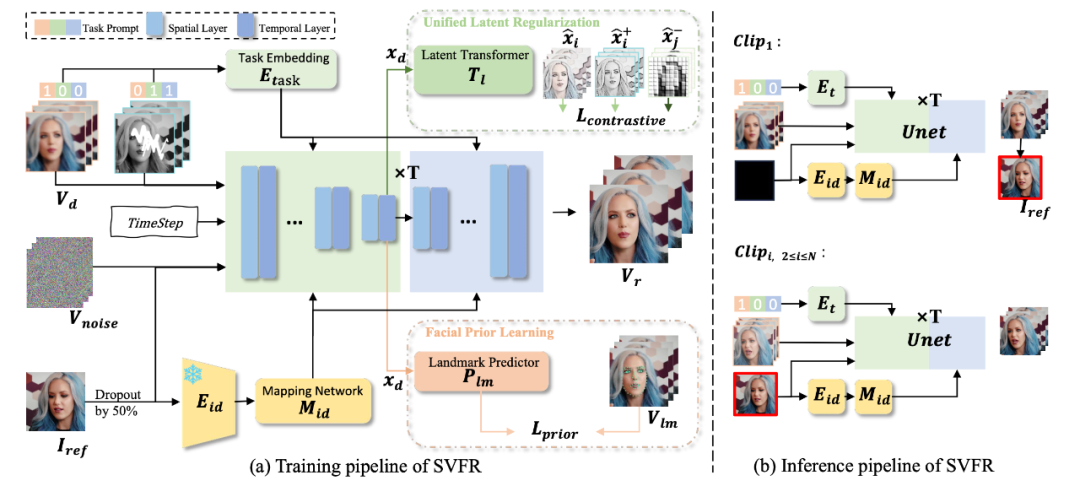
简介:人脸修复(FR)是图像和视频处理领域的一个重要方向,主要关注从降质的输入中重建高质量的人物肖像。尽管图像人脸修复(FR)已有显著进展,但对视频人脸修复(FR)的探索仍然相对较少。此外,传统的人脸修复通常侧重于提升分辨率,可能未充分考虑到诸如人脸上色和补全等相关任务。本文提出了一种新颖的方法用于广义视频人脸修复(GVFR)任务,该方法整合了视频BFR、补全和上色任务,且通过实验证明这些任务能互有增益。本文设计了一个统一的框架——稳定视频人脸修复(SVFR),利用稳定视频扩散(SVD)的生成和运动先验,并通过统一的人脸修复框架融入任务特定信息。本文引入了可学习的任务嵌入以增强任务识别能力,同时采用了一种新颖的统一潜在正则化(ULR)策略,鼓励不同子任务之间共享特征表示学习。为了进一步提升修复质量和时序稳定性,本文引入了面部先验学习和自参考优化作为训练和推理中的辅助策略,所提出的框架有效地结合了这些任务的互补优势,增强了时序一致性并实现了优越的修复质量。该工作推动了视频人脸修复的最新进展,并为广义视频人脸修复奠定了新的范式。
该论文的共同第一作者是厦门大学人工智能研究院2022级硕士生王志遥和2018级硕士毕业生陈旭,共同通讯作者是周奕毅副教授和朱俊伟(腾讯优图),由徐程明(腾讯优图)、汪铖杰(腾讯优图)、2024级博士生刘宇琪、纪荣嵘教授等共同合作完成。
07
UCOD-DPL: Unsupervised Camouflaged Object Detection via Dynamic Pseudo-label Learning
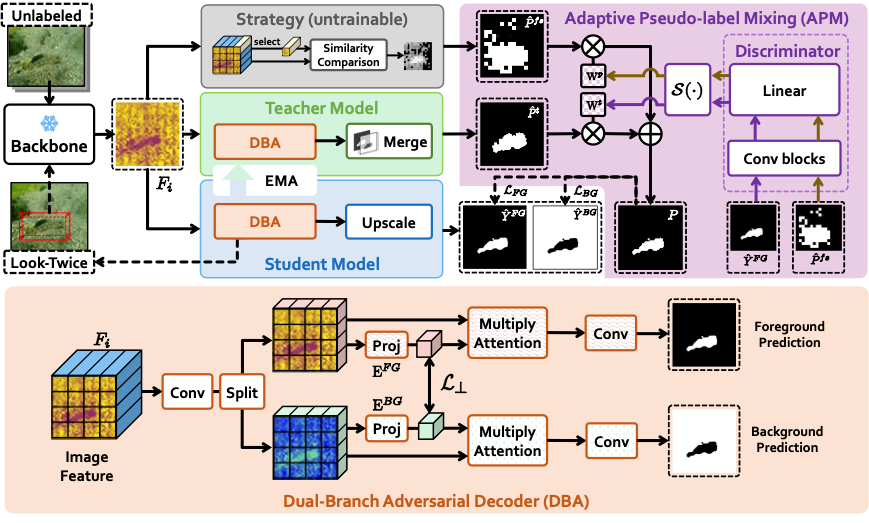
简介:无监督伪装目标检测因其无需依赖大量像素级标注而受到广泛关注。现有方法通常采用固定策略生成伪标签,并使用1x1卷积层作为简单解码器进行训练,导致其性能远低于全监督方法。现有方法存在两个主要缺陷:1) 固定策略构建的伪标签通常包含大量噪声,模型容易学习到错误的知识;2) 伪标签分辨率较低且前景与背景像素之间存在严重混淆,简单解码器难以有效捕捉和学习伪装目标的语义特征,尤其是在处理小尺度目标时表现较差。为了解决上述问题,本文提出了一个动态伪标签驱动的无监督伪装目标检测框架(UCOD-DPL)。该方法包括自适应伪标签融合模块(APM)、双分支对抗解码器(DBA)以及“二次观察”机制(Look-Twice Mechanism)。其中,APM模块自适应融合由固定策略和教师模型生成的伪标签,以防止模型过度拟合错误知识,同时保持自我纠正能力;DBA解码器通过对不同分割目标的对抗学习,引导模型克服伪装目标的前景-背景混淆问题;“二次观察”机制模拟人眼观察伪装目标时的缩放过程,对小尺度目标进行二次细化处理。实验结果表明,本文的方法表现优异,甚至超越了部分现有的全监督方法。
该论文第一作者是厦门大学信息学院2024级硕士生颜玮琦,通讯作者是张声传副教授,由张岩工程师、曹刘娟教授等合作完成。
08
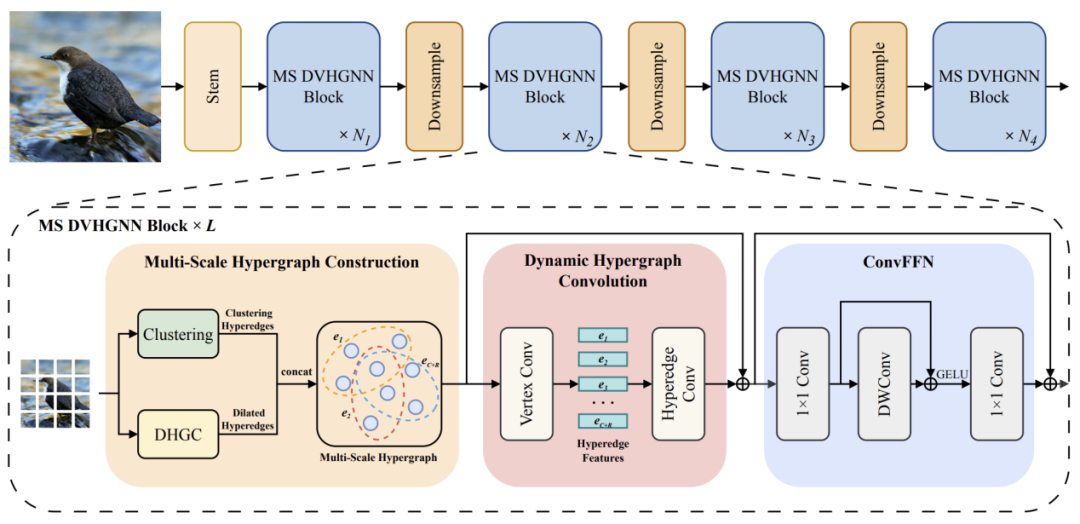
DVHGNN: Multi-Scale Dilated Vision HGNN for Efficient Vision Recognition
简介:近来,视觉图神经网络(ViG)在计算机视觉领域引起了广泛关注。然而,视觉图神经网络仍面临两个关键问题,包括K近邻(KNN)构图导致的二次计算复杂度以及普通图只能建模数据之间的成对关系。为了解决上述挑战,该文提出了一种新颖的视觉架构,称为空洞视觉超图神经网络(DVHGNN)。该方法设计了聚类和膨胀超图构建方法,能够自适应地捕捉数据样本之间的多尺度依赖关系。此外,提出了一种动态超图卷积机制,实现了超图层级上的视觉特征自适应消息传递。在基准图像数据集进行的实验表明:提出的DVHGNN优于主流的卷积神经网络、视觉Transformer、视觉多层感知机、视觉图神经网络以及视觉Mamba。
该论文的共同第一作者是厦门大学信息学院2023级硕士生李曹硕和信息学院2024级博士生李谭哲,通讯作者是金泰松副教授,由胡晓斌(腾讯优图)、罗栋豪(腾讯优图)共同合作完成。
09
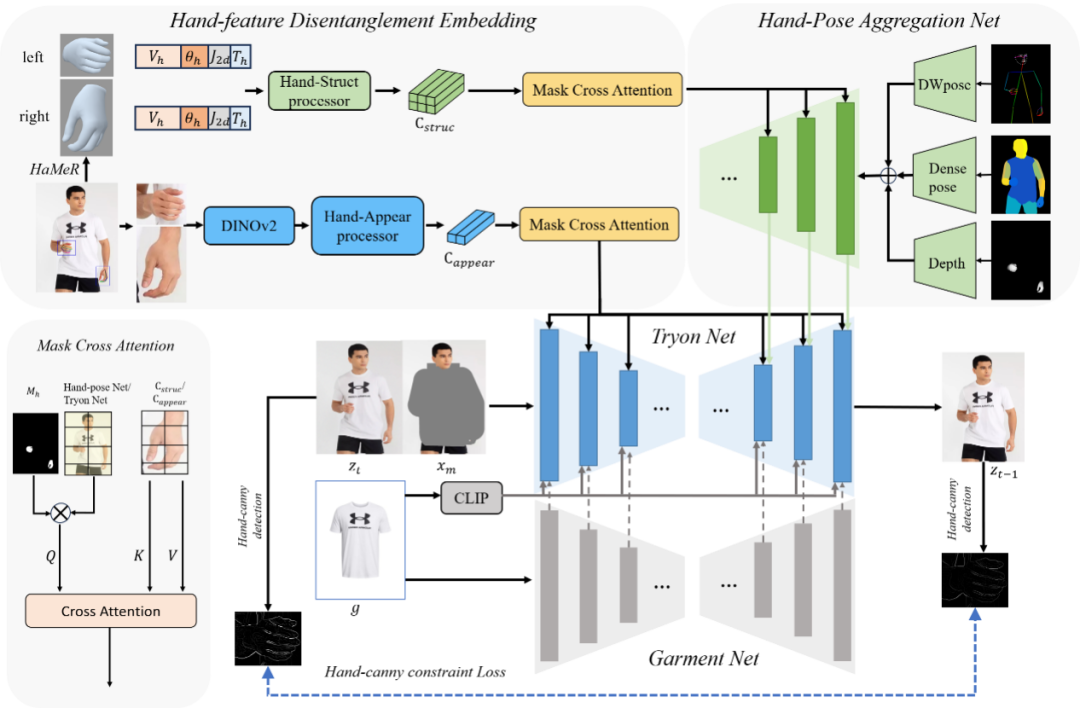
VTON-HandFit: Virtual Try-on for Arbitrary Hand Pose Guided by Hand Priors Embedding
简介:该文提出一种基于手部先验增强的虚拟试衣方法VTON-HandFit,以解决扩散模型在手部遮挡场景下的服装失真问题。首先,基于ControlNet架构定制了手部姿势聚合网络,能够显式且自适应地编码全局手部及人体姿势先验。其次,为了充分挖掘手部相关结构与视觉信息,提出了手部特征解耦嵌入模块将手部先验解耦为手部结构参数特征和视觉外观特征,并设计了掩码交叉注意力机制实现特征解耦嵌入。最后,构建手部边缘约束损失,能够从原始模特图像的手部轮廓中更好地学习结构边缘信息。在公共数据集及自建Handfit-3K手部遮挡数据集进行的实验表明:该文提出的方法优于现有主流方法。
该论文共同第一作者是厦门大学信息学院 2022级硕士生梁宇杰和胡晓彬(腾讯优图),共同通讯作者是金泰松副教授和罗栋豪(腾讯优图),由姜博源(腾讯优图)、汪铖杰(腾讯优图)、纪荣嵘教授等共同合作完成。
10
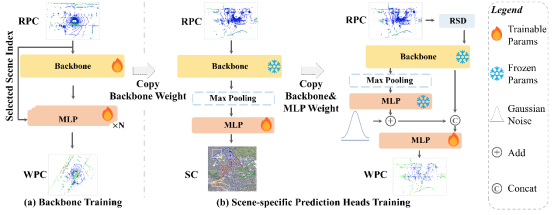
LightLoc: Learning Outdoor LiDAR Localization at Light Speed
简介:现有基于隐式表征的定位方法通常需针对每个新场景进行长达数天的模型训练,难以满足自动驾驶等时间敏感应用需求。为此,本文提出LightLoc方法,旨在高效快速完成新场景定位。LightLoc采用冻结场景无关编码器、仅训练场景特定回归器的策略,并创新性地引入样本分类指导和冗余样本下采样技术,从而显著降低训练时间与数据冗余。实验表明,LightLoc仅需1小时即可达到最优性能,训练速度较现有方法提升50倍。
该论文第一作者是厦门大学信息学院2021级博士生李文,通讯作者是王程教授、于尚书博士(南洋理工大学)。由刘晨、刘敦强、周寅(GAC R&D Center)、沈思淇长聘副教授、温程璐教授共同完成。
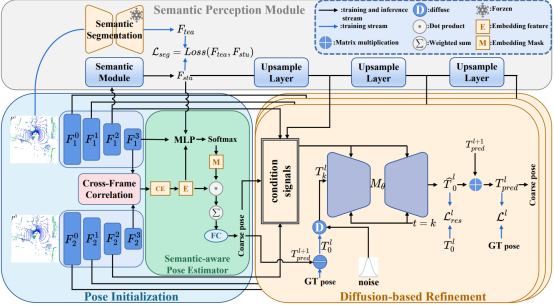
11
DiffLO:Semantic-Aware LiDAR Odometry with Diffusion-Based Refinement简介:LiDAR里程计方法在场景理解不足和噪声干扰的情况下容易出现不准确的位姿估计。针对这一挑战,本文提出了一种基于扩散优化的语义感知LiDAR里程计网络(DiffLO)。为应对动态、低纹理等复杂场景的影响,本文通过语义蒸馏方法,将语义信息融入里程计任务中,使网络更关注对位姿估计有益的物体。此外,本文提出了基于扩散的优化方法,利用与位姿相关的特征作为条件约束,通过生成多样性迭代优化位姿估计。在KITTI里程计数据集上的实验表明,该方法超过了近期所有基于学习的方法。该论文第一作者是厦门大学信息学院2023级硕士生黄泳树,通讯作者是王程教授。由刘晨、朱明航、敖晟助理教授、温程璐教授共同合作完成。
12
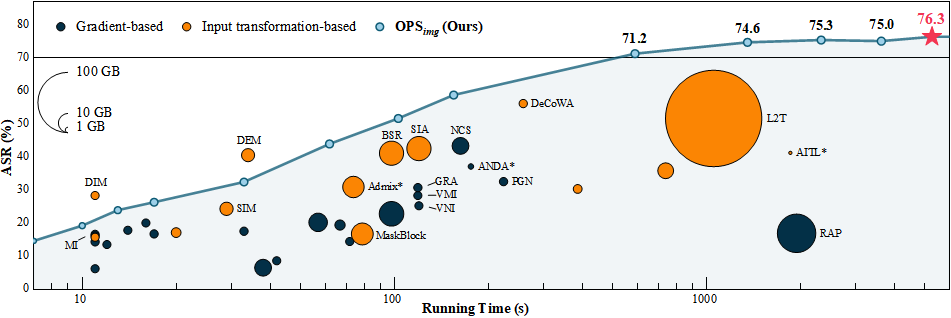
Boosting Adversarial Transferability through Augmentation in Hypothesis Space
简介:对抗样本的可转移性特性指针对一个模型生成的对抗样本可能对其他模型同样有效。现有研究通过设计复杂的数据和模型交互机制来提升可转移性,但效果有限且与数据模态强相关。本文发现模型的泛化性和对抗样本的可转移性之间存在镜像关系,可通过增强假设空间来提高可转移性的可能性。为此,本文设计了一种基于扰动的随机优化攻击OPS,利用输入变换算子和随机扰动生成更具可转移性的对抗样本。实验表明,OPS在图像和点云上均显著优于现有最优方法,在性能和效率方面表现优异。
该论文第一作者是厦门大学计算机科学与技术系2023级硕士生郭宇,通讯作者是王程教授。由刘伟权(集美大学)、徐青山(南洋理工大学)、郑士均、黄舒俊、臧彧副教授、沈思淇长聘副教授、温程璐教授共同合作完成。
13
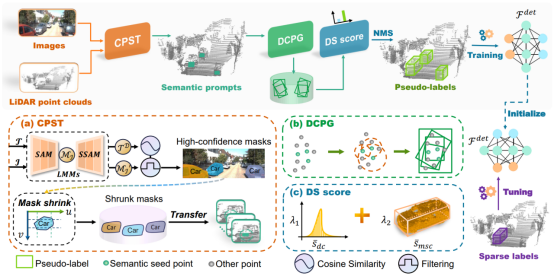
SP3D: Boosting Sparsely-Supervised 3D Object Detection via Accurate Cross-Modal Semantic Prompts
简介:稀疏监督目标检测方法在标注量极度缺乏时很难保持性能。本文提出SP3D方法,利用跨模态的语义提示显式增强稀疏监督3D目标检测性能。本文首先引入可信点语义迁移模块,利用多模态大模型和图像数据生成高可信度的跨模态语义提示。其次,将语义提示作为种子点,通过动态伪标签生成策略和分布形状得分生成高质量伪标签。最后,使用少量的标注数据对检测器进行微调。在KITTI和Waymo数据集上的实验结果表明,SP3D显著提升了SoTA稀疏监督目标检测器的性能,在零样本设置中也表现优异。
该论文第一作者是厦门大学信息学院2023级博士生赵世佳、2022级博士生夏启明,通讯作者是温程璐教授。由郭徐晟、邹普凡、郑茂基、吴海、王程教授共同合作完成。
14
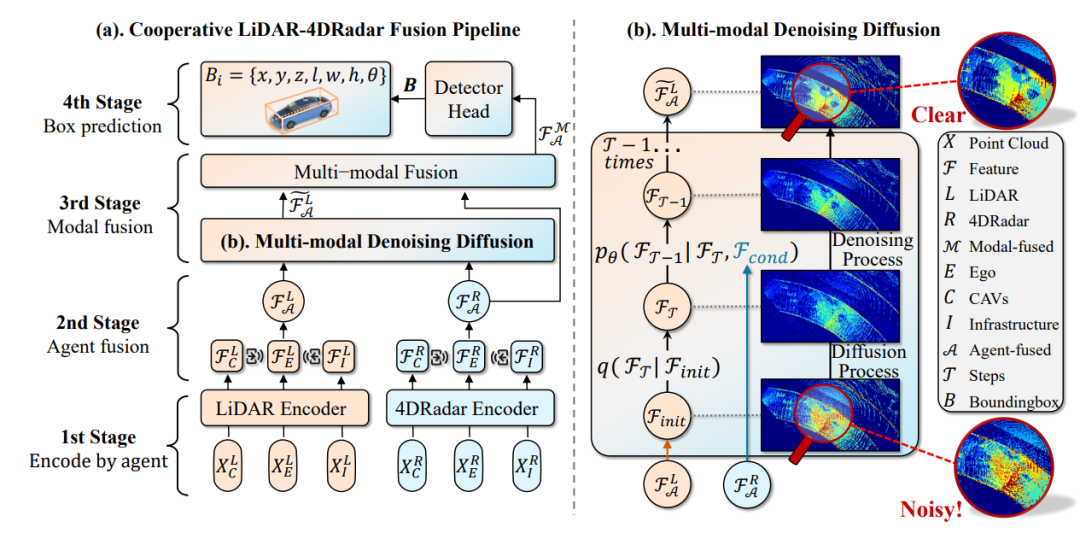
V2X-R: Cooperative LiDAR-4D Radar Fusion for 3D Object Detection with Denoising Diffusion
简介:当前多智能体协同感知系统在恶劣天气条件下性能显著下滑。4D 毫米波雷达可提供多普勒和额外的几何信息,本文提出了一种新颖的LiDAR-4D Radar融合目标检测框架,并提出4D Radar特征辅助的LiDAR去噪扩散模块(MDD)。此外,本文构建了V2X-R,首个包含激光雷达、相机和 4D 毫米波雷达的V2X仿真数据集。实验表明,本文的方法在 V2X-R 数据集上表现优异,且MDD 模块可有效提升模型在恶劣天候下的性能。数据集和代码已开源:https://github.com/ylwhxht/V2X-R
该论文第一作者是厦门大学AI研究院2024级博士生黄勋,通讯作者是温程璐教授。由王锦龙、陈思衡副教授(上海交通大学)、杨必胜教授(武汉大学)、Xin Li教授(Texas A & M University)、王程教授共同合作完成。
15
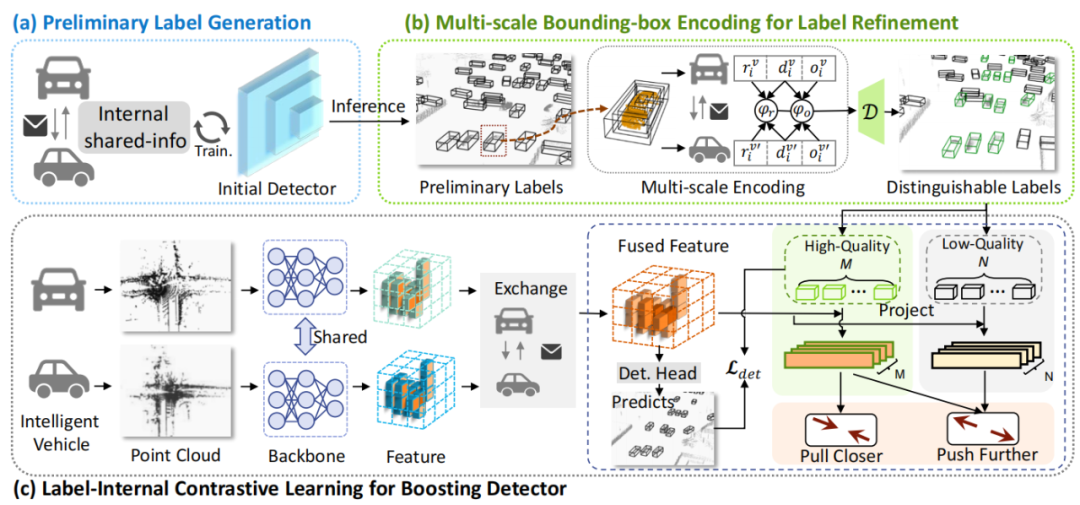
Learning to Detect Objects from Multi-Agent LiDAR Scans without Manual Labels
简介:无监督3D目标检测在离线标注中面临数据稀疏性和视角限制的问题,导致基于聚类拟合生成的伪标签质量低。为此,本文提出了一种新颖的无监督方法DotA,从多智能体间的点云扫描中学习检测目标,无需外部标注。DOtA通过协作智能体共享的姿态和形状信息初始化检测器并推断初步标签,再结合智能体间的互补观测进行多尺度编码区分高低质量标签,用于指导特征学习。实验表明,DOtA在V2V4Real和OPV2V数据集上优于现有最优方法,并验证了其在协作感知框架下的有效性。
该论文第一作者是厦门大学信息学院2022级博士生夏启明,通讯作者是温程璐教授。由林文铠、项浩恩、黄勋、陈思衡副教授(上海交通大学)、董震教授(武汉大学)、王程教授共同合作完成。
16
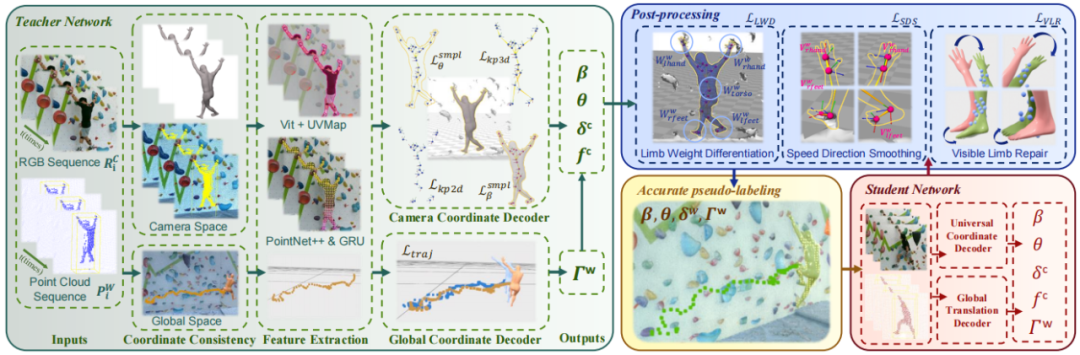
ClimbingCap: Multi-Modal Dataset and Method for Rock Climbing in World Coordinate
简介:攀岩是一类新兴的运动,风靡全球备受青睐。我国在2024年奥运会上获得了两枚攀岩银牌,通过攀岩动捕算法对攀岩动作进行精细分析能够有助于提高运动员训练效果,提高比赛成绩。但是现有国际上动作捕捉算法对攀岩动作的准确度较低,有两个原因,一是现有的攀岩数据集数量有限,二是现有攀岩算法没有充分考虑全局坐标系4D人体攀爬运动恢复。本文收集了一个大规模、质量高且具有挑战性的攀爬运动数据集AscendMotion,提出了采用RGB相机和激光雷达在全局坐标系中对4D人体攀爬运动进行运动恢复的动捕算法ClimbingCap。实验验证了该数据集的质量以及本文提出的攀岩动捕算法的有效性。
该论文的第一作者是厦门大学信息学院2023级博士生颜明、2024级硕士生林心成,通讯作者是沈思淇长聘副教授,由钟齐鑫(国家攀岩队)、钟林财(浙江省攀岩队)、马月昕助理教授(上海科技大学)、许岚助理教授(上海科技大学),罗裕华、范书琪、戴雨笛、温程璐教授、王程教授共同合作完成。

17
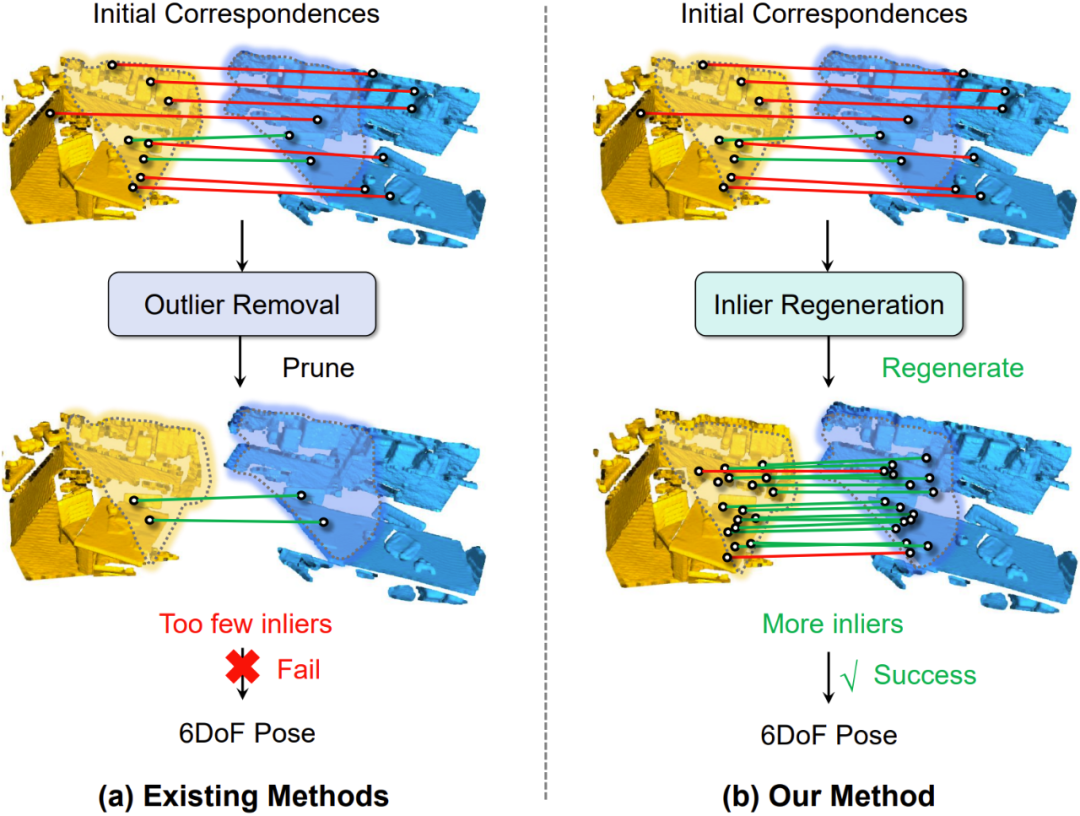
Progressive Correspondence Regenerator for Robust 3D Registration
简介:现有的对应关系优化方法无法在极端离群点比例下正确识别准确的对应关系。为此,本文提出了一种名为Regor的渐进式点云配准方法。通过渐进式的局部匹配与全局优化,该方法能够在大量离群点的情况下,生成高质量的匹配结果。大量室内和室外数据集的实验结果表明,所提方法显著优于现有的离群点去除技术。最为关键的是,Regor比现有离群点去除方法获得了10倍以上的正确对应关系。
该论文第一作者是厦门大学信息学院敖晟助理教授、赵桂瑜(北京理工大学),通讯作者是郭裕兰教授(中山大学)。由张晔副研究员(中山大学)、徐凯教授(国防科技大学)共同完成。
18
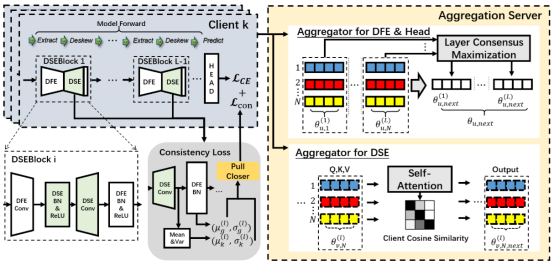
Federated Learning with Domain Shift Eraser简介:联邦学习(FL)中用户的数据域转移现象常常阻碍用户模型学习一致的表示空间。为此,本文提出了一种个性化联邦FL框架——联邦域偏差消除器(FDSE),通过差异化消除每个客户的领域偏差并增强其共识来提升模型性能。具体而言,FDSE将模型前向传播过程建模为一个迭代的去偏过程,交替进行共识增强的特征提取和个性化域偏差消除。实验表明了FDSE方法在准确性、效率和泛化性方面的优势。该论文第一作者是厦门大学信息学院2022级博士生王铮,通讯作者是王程教授。由王子徽博士(鹏城实验室),王郑,范晓亮高级工程师共同合作完成。
19
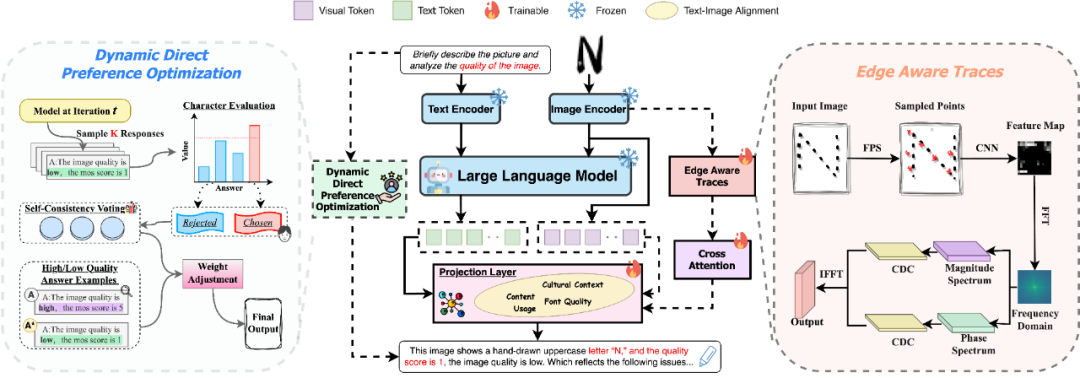
Font-Agent: Enhancing Font Understanding with Large Language Models
简介:随着生成模型的蓬勃发展,字体生成取得了显著进展,但对其可解释性与评估仍然不足。为此,本文构建了含13.5万字体-文本对的多模态数据集DFD,涵盖多种生成字体类型、语言描述与质量注释,为字体分析模型的训练与评估奠定了坚实基础。基于此,本文提出了VLM架构的Font-Agent,引入EAT模块捕捉字体笔画边缘信息,并通过D-DPO策略高效微调模型,赋予解释性问答能力。实验证明,Font-Agent在DFD及其他公开数据集上均表现突出,不仅能精准评估生成字体质量,也能深度理解其内容。在多样化数据集上的实验也验证了其泛化性能,彰显了Font-Agent的潜力。
该论文第一作者是厦门大学信息学院2024级博士研究生赖映鑫,通讯作者是罗志明副教授。由许璀杰(图形起源),史海天(图形起源),杨国庆、李晓宁、李绍滋教授共同合作完成。
20
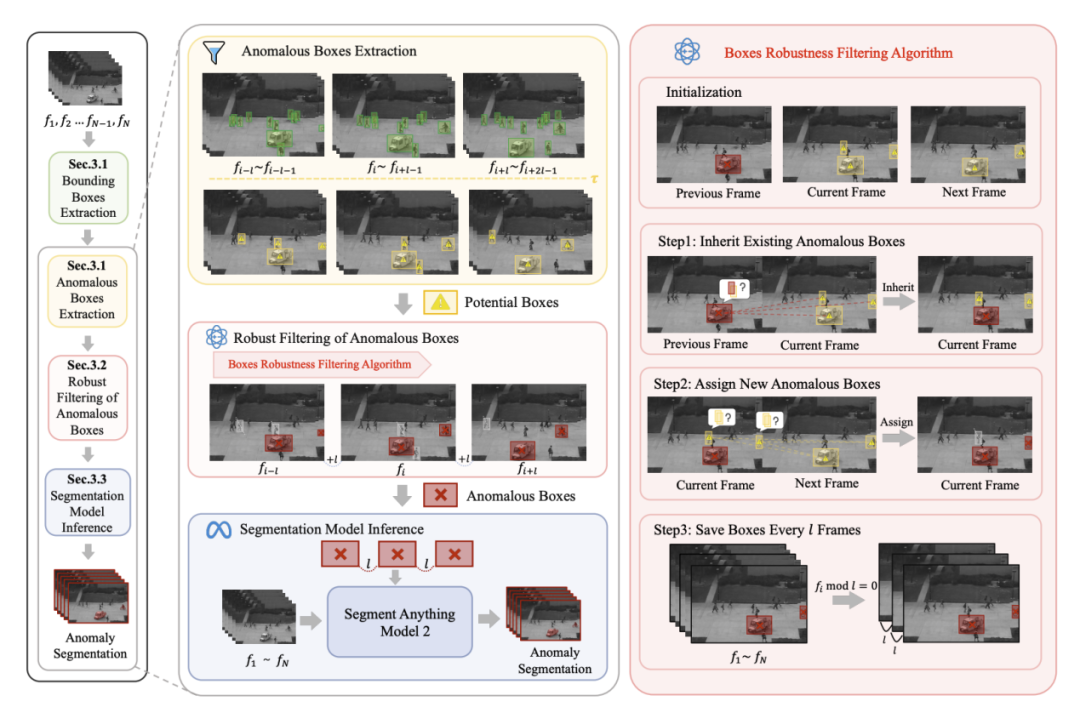
Track Any Anomalous Object: A Granular Video Anomaly Detection Pipeline简介:本文提出了一种创新的视频异常检测框架,该框架引入了一种细粒度视频异常检测框架,首次将多个细粒度异常对象的检测整合到一个统一的框架中。现有方法主要聚焦于识别视频中的异常对象,通常通过检测异常帧或异常目标来实现。然而,这些方法往往忽略了更精细的异常像素级分析,从而限制了其捕捉更广泛异常的能力。与传统方法在每个时间点为每个像素分配异常分数的方式不同,本文方法将问题转化为异常目标的像素级跟踪。通过将异常分数与图像分割和视频跟踪等后续任务相结合,该方法无需人工设定阈值,从而实现了更加精确的异常定位,即使在长时间且具有挑战性的视频序列中也能表现出色。在大规模数据集上的实验结果表明,该方法达到了最先进(state-of-the-art)的性能,为视频异常检测提供了一种实用、细粒度且全局化的解决方案,推动了该领域的新进展。该论文共同第一作者是厦门大学信息学院2023 级硕士生黄誉之和香港中文大学博士生李宸鑫,通讯作者为信息学院黄悦教授。此外,该研究由信息学院2024级研究生张海涛和丁兴号教授共同合作完成。
21
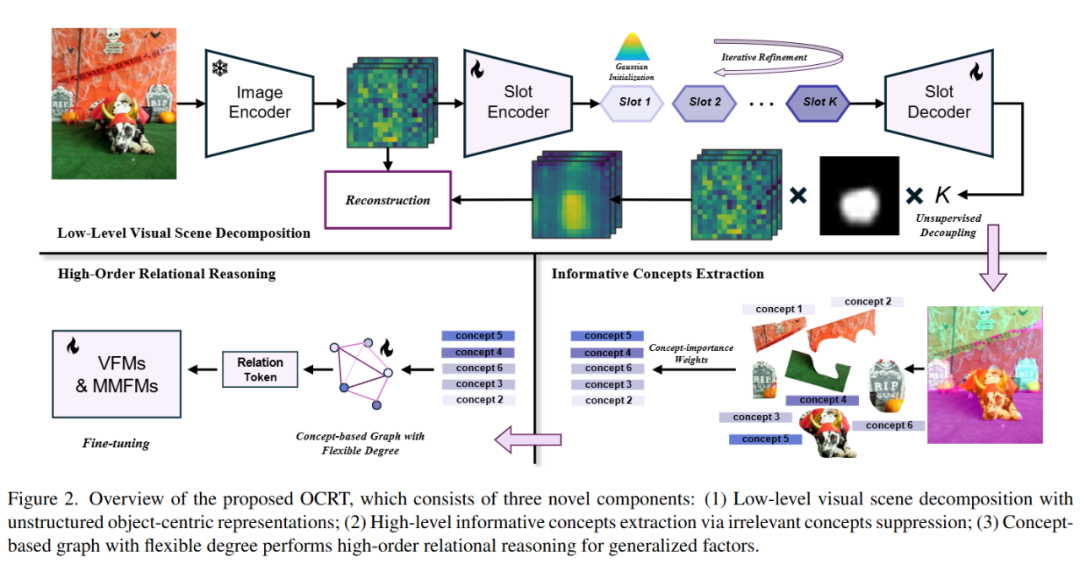
OCRT: Boosting Foundation Models in the Open World with Object-Concept-Relation Triad简介:尽管现有的基础模型(FMs)在多种下游任务中取得了显著进展,但在开放世界中面对分布偏移、弱监督或恶意攻击时,其泛化能力显著下降。与以往针对特定任务或模型的改进方法不同,本文从人类认知科学的角度出发,发现从密集的视觉输入中提取稀疏的高级概念和复杂的关系结构可以有效提升模型的泛化能力。基于此,本文提出了一种新颖的框架——目标-概念-关系三元组(OCRT)。OCRT通过无监督解耦和迭代优化,将视觉场景中的对象与一组以对象为中心的表示绑定,并将这些表示投影到模型易于解释的语义概念空间中,同时估计其重要性以过滤掉无关元素。进一步,OCRT构建了一个基于概念的图结构,用于提取高阶因子并促进这些概念之间的关系推理。为了验证OCRT的有效性,本文将其实用于两种代表性基础模型——SAM和CLIP,并分别命名为OCRT-SAM和OCRT-CLIP。广泛的实验表明,OCRT在多个下游任务上显著提升了SAM和CLIP的泛化能力和鲁棒性。该论文共同第一作者是厦门大学信息学院2022 级硕士生唐路垚和 2024 级博士生袁与炫,通讯作者是黄悦教授和陈超奇助理教授(深圳大学),由张坤教授(卡内基梅隆大学、默罕默德·本·扎耶德人工智能大学)共同合作完成。
22
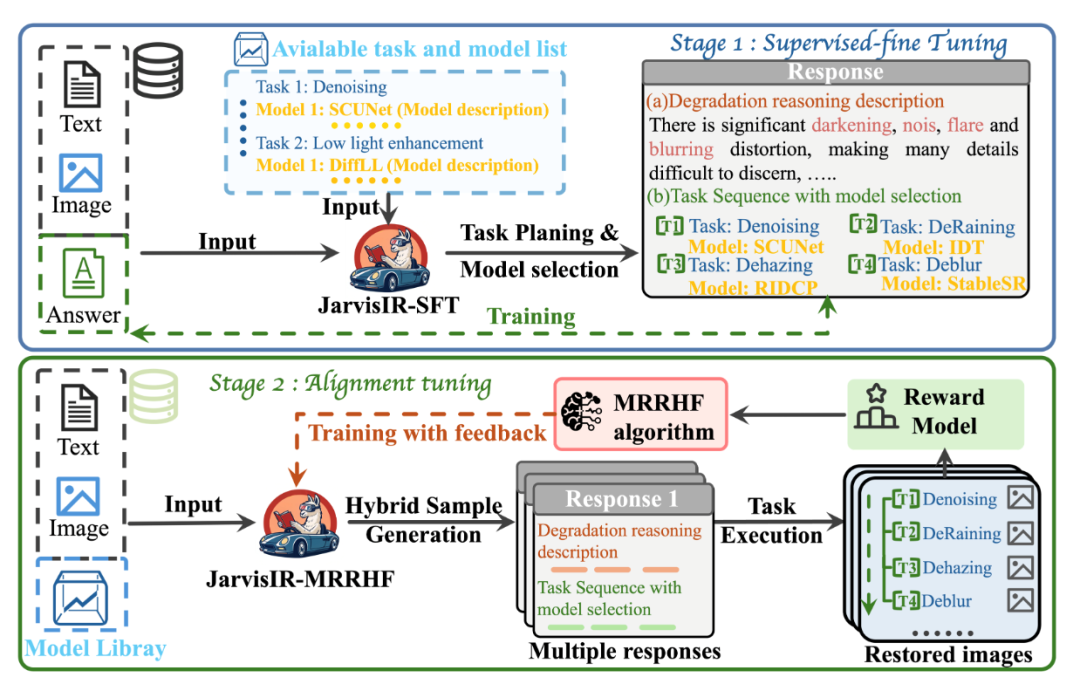
JarvisIR: Elevating Autonomous Driving Perception with Intelligent Image Restoration简介:以视觉为中心的感知系统在复杂自然环境中常面临不可预测且相互关联的天气退化问题。现有解决方案存在明显局限,既可能依赖特定退化先验知识,又容易受到显著领域差异的影响。为实现真实场景下的鲁棒自主运行,本文提出JarvisIR,一种基于视觉语言模型的智能体,利用VLM作为控制器来统筹多个专家修复模型。该系统采用包含监督微调与人类反馈对齐的双阶段创新框架,有效提升系统鲁棒性、减少模型幻觉,并增强恶劣天气下的泛化能力。针对真实场景中配对数据稀缺的挑战,人类反馈对齐机制使VLM能够通过无监督方式在大规模真实数据上高效微调。为支撑JarvisIR的训练与评估,本文构建了CleanBench综合数据集,包含15万组合成数据和8万组真实数据的高质量指令-响应对。实验结果表明,JarvisIR展现出卓越的决策与修复能力:在CleanBench-Real测试集上,其感知指标平均提升达50%。该论文主要共同第一作者是厦门大学信息学院2023 级硕士生林云龙和林子旭,通讯作者为信息学院丁兴号教授,由潘攀望(字节跳动)、陈浩宇(香港科技大学)、李文博(华为诺亚方舟实验室)等共同合作完成。
23
Federated Semi-Supervised Learning via Pseudo-Correction Utilizing Confidence Discrepancy
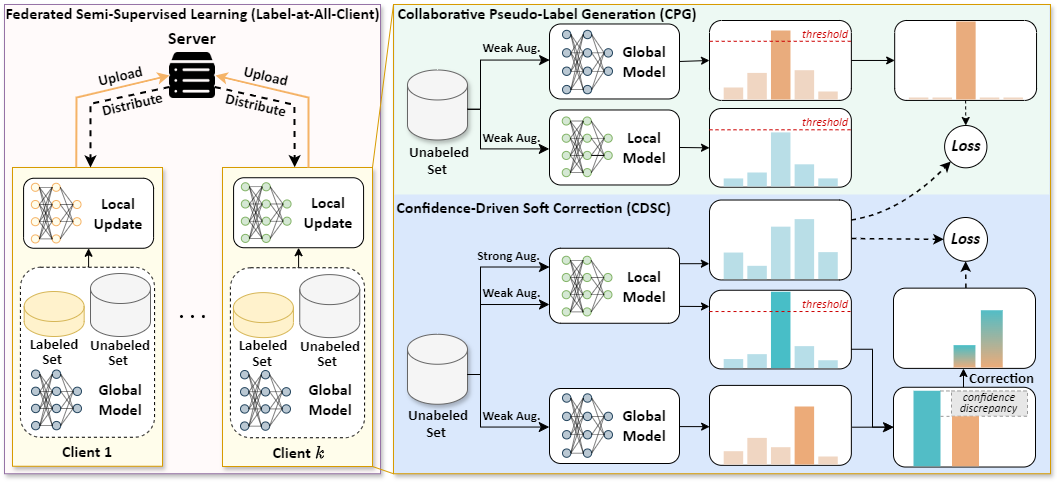
简介:联邦半监督学习(FSSL)旨在利用各客户端的未标注数据,在仅有有限标注数据的情况下,训练一个具备强泛化能力的全局模型,但数据异质性作为联邦学习的固有特性,显著降低了伪标签的质量。本文深入探讨了FSSL问题,并揭示:(1) 数据异质性加剧了伪标签的不匹配问题,进一步降低了模型性能并影响收敛性;(2) 随着异质性的增加,本地模型和全局模型的预测趋势逐渐偏离。基于上述发现,本文提出了一种简单而高效的方法SAGE,根据置信度差异灵活修正伪标签。这一策略有效缓解了由于错误伪标签导致的性能下降问题,并增强了本地模型与全局模型之间的一致性。实验结果表明,SAGE在性能和收敛性方面均优于现有的FSSL方法。
该论文的第一作者是厦门大学23级硕士生刘艺杰,通讯作者是卢杨助理教授,由尚心怡(UCL)、张逸群(广东工业大学)、宫辰(上海交通大学)、Jing-Hao Xue(UCL)、王菡子教授等共同合作完成。
24
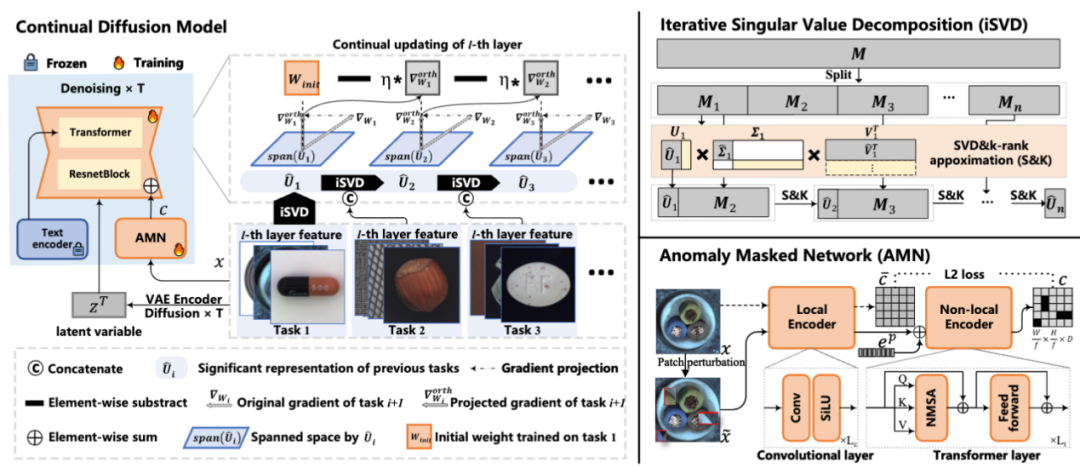
One-for-More: Continual Diffusion Model for Anomaly Detection
简介:随着生成模型的兴起,在生成框架内统一所有任务的趋势日益增长。生成类方法在异常检测任务中也有广泛应用,这类方法通常利用扩散模型在给定任意异常图像时生成或重建正常本实现异常的定位。然而,本工作的研究发现,扩散模型存在严重的“忠实幻觉”和“灾难性遗忘”问题,无法满足不可预测的模式增量。为了缓解上述问题,本工作提出了一种持续扩散模型,该模型使用梯度投影来实现稳定的持续学习。梯度投影通过将梯度投影到旧任务知识的正交方向来实现对已有知识的保留。但扩散模型的马尔可夫推理会极大增加梯度投影的内存成本。为此,本工作提出了一种基于线性表示传递性质的迭代奇异值分解方法,该方法消耗不仅节省了90%以上的内存,而且几乎不会造成性能损失。最后,考虑到扩散模型对正常图像“过拟合”的风险,本工作提出了一种异常掩码网络来增强扩散模型的条件机制。对于持续异常检测,本工作的方法在MVTec和VisA的17/18个设置中取得了SOTA。代码即将开源:https://github.com/FuNz-0/One-for-More
该论文第一作者是华东师范大学李晓凡,由华东师范大学和厦门大学曲延云教授、陈卓等共同合作完成。