近日,信息学院于计算机视觉领域顶级会议ICCV 2021(IEEE International Conference on Computer Vision)和多媒体领域顶级会议ACM MM 2021(ACM International Conference on Multimedia)上发表多项重要研究成果:
1、Architecture Disentanglement for Deep Neural Networks(发表于ICCV 2021)
本文的第一作者是信息学院人工智能系2019级博士生胡杰,通讯作者是信息学院计算机科学与技术系曹刘娟副教授。本文通过解耦神经网络来探究其可解释性,将对神经网络的理解从单神经元、单层,拓展到了从输入到输出整个推理过程。通过神经网络解耦,本文揭示了神经网络可以按照任务被拆解成子结构,并且最高层语义并不一定出现在神经网络最深层。最后,本文探讨了子结构相似是导致神经网络分类错误的原因之一。

2、ReCU: Reviving the Dead Weights in Binary Neural Networks(发表于ICCV 2021)
本文的第一作者是信息学院人工智能系2019级硕士生许子涵,通讯作者是信息学院人工智能系纪荣嵘教授。本文指出了二值神经网络(BNN)中存在难以更新的失活权重Dead weights,提出使用一个权衡量化误差和信息熵的整流钳制单元(Rectified clamp unit, ReCU) 重新赋予失活权重活性,使其更容易被更新,并在多个数据集和模型上验证了该算法的有效性。
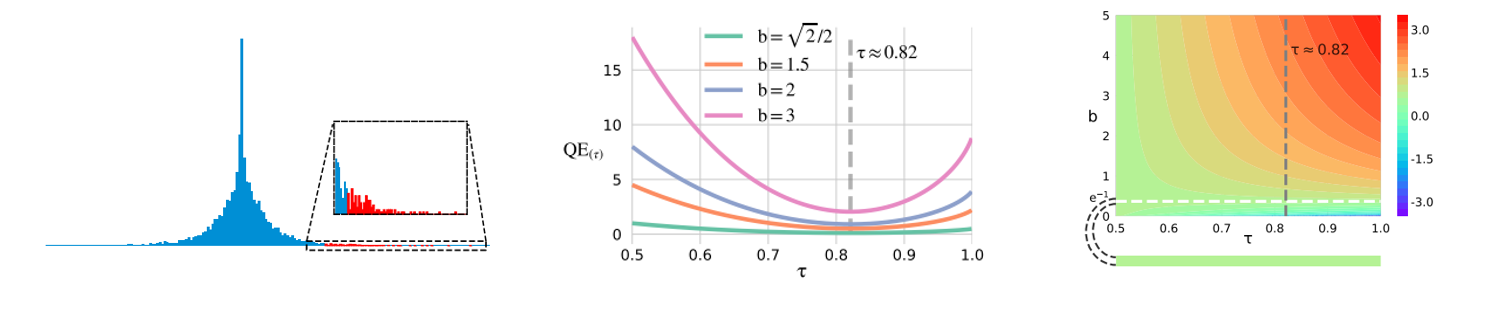
3、Aha! Adaptive History-driven Attack for Decision-based Black-box Models(发表于ICCV 2021)
本文的第一作者是信息学院人工智能系2019级博士生李杰,通讯作者是信息学院人工智能系纪荣嵘教授。本文针对硬标签查询的黑盒攻击问题,提出了一种有效利用历史先验动态更新的攻击算法(Adaptive History-driven Attack)。该算法从目标类别图片出发,采用改进的随机游走策略以接近原始图像。为了加速优化,算法将之前的查询信息作为先验知识指导当前采样。同时为了平衡迭代过程中的探索与利用,算法基于与输入图片距离缩小的实际值与期望值的比值动态调整两个方向的系数。该算法有效提升硬标签黑盒攻击效率,并在模拟场景和真实线上API场景下得到了验证。
4、Occlude Them All: Occlusion-Aware Mask Network for Person Re-identification(发表于ICCV 2021)
本文的第一作者是信息学院计算机科学与技术系2018级硕士生陈珮娴,通讯作者是信息学院戴平阳高级工程师。本文针对遮挡情况下的行人重识别问题,利用注意力机制判断图片的遮挡位置,在测试阶段提出occlusion unification策略消除遮挡类型的分类歧义,并提出了一种适用于遮挡问题的数据增强方法。本模型以更低的模型复杂度和测试时间,在该任务的常用公开数据集上均取得了最优性能。
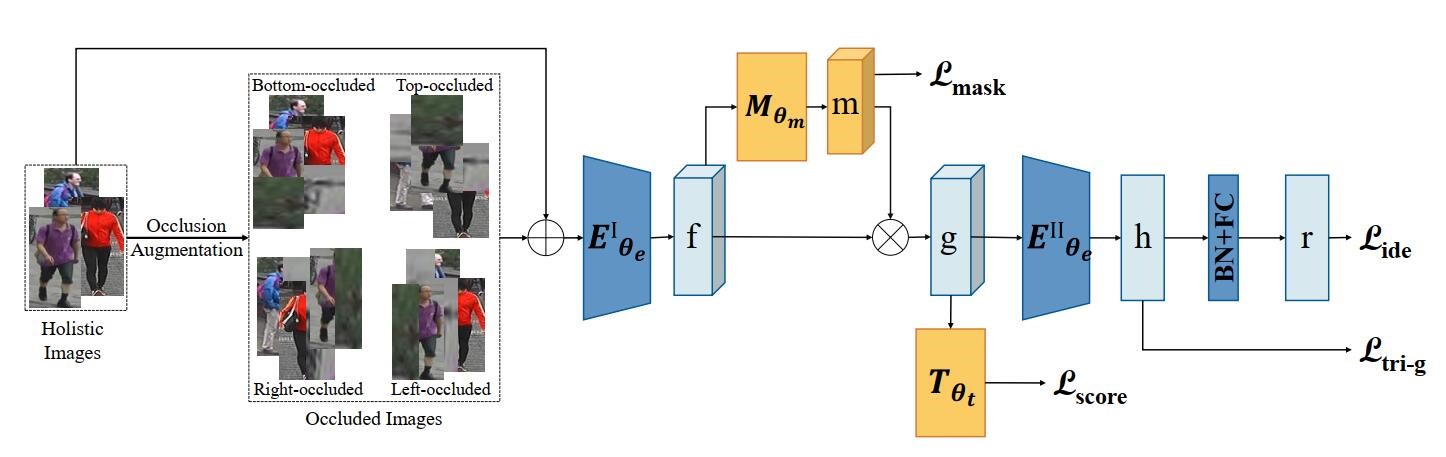
5、Parallel Detection-and-Segmentation Learning for Weakly Supervised Instance Segmentation(发表于ICCV 2021)
本文的第一作者是信息学院人工智能系2017级博士生沈云航,通讯作者是信息学院人工智能系纪荣嵘教授。本文从自顶而下和自底向上的实例分割方法启发,为弱监督实例分割任务提出一种统一平行检测分割的学习框架。特别地,检测模块和常见的弱监督目标检测一样,而分割模块采用自监督学习来学习类别无关的前景分割,然后再通过自训练来逐步获得特定类别的分割结果。最后,本文在多个数据集上验证了该算法的有效性。
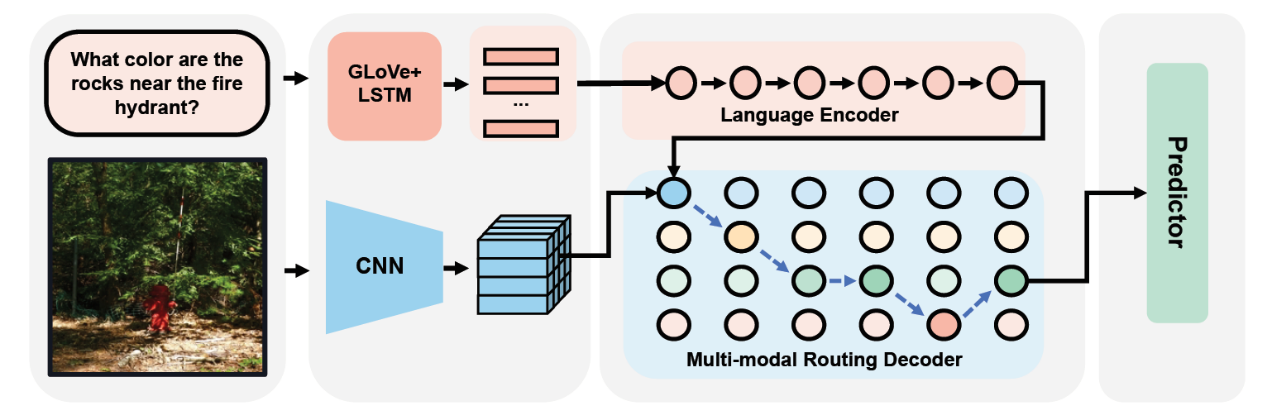
6、TRAR: Routing the Attention Spans in Transformers for Visual Question Answering(发表于ICCV 2021)
本文的第一作者是信息学院信息与通信工程系流动站博士后周奕毅,通讯作者是信息学院人工智能系孙晓帅副教授。本文针对Transformer在视觉与语言任务中的全局与局部注意力建模选择问题,提出了一种全新的网络动态规划机制,叫做Transformer Routing (TRAR)。TRAR可以根据模型每一步的输入特征动态选择Transformer的视觉注意力范围,从而为每个多模态样本构建最佳的模型推理路径。此外,通过路径选择问题的有效定义,TRAR可以将动态网络的额外开销降低到几乎可以忽略不计。所提出的方法在VQA和REC两个多模态任务中得到了有效验证。
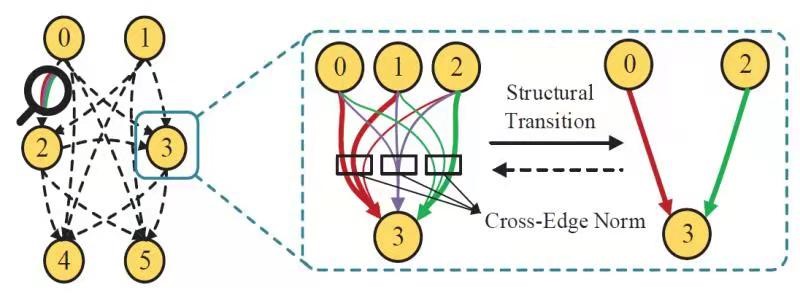
7、EC-DARTS: Inducing Equalized and Consistent Optimization into DARTS(发表于ICCV 2021)
本文的第一作者是信息学院人工智能系2020级博士生周勤勤,通讯作者是信息学院计算机科学与技术系曹刘娟副教授。本文提出在可微结构搜索中引入均衡和一致的优化(Inducing Equalized and Consistent Optimization into DARTS,EC-DARTS),分析了搜索空间的不同算子之间存在的不均衡性以及搜索阶段和重训阶段的结构之间的不一致性问题。通过提出的跨边正规化方法(CrossEdge Normalization)处理不同算子之间的不公平竞争,使对不同算子的搜索优化过程保持相对均衡的状态。为了进一步提高搜索结构的预测性能和真实性能之间的相关性,提出结构转换策略(Induced Structural Transition),通过在搜索过程中构建辅助模型继承超网络的模型权重信息和重训阶段模型的结构信息来提高模型相关性。最终在多个数据集上验证了方法的有效性。
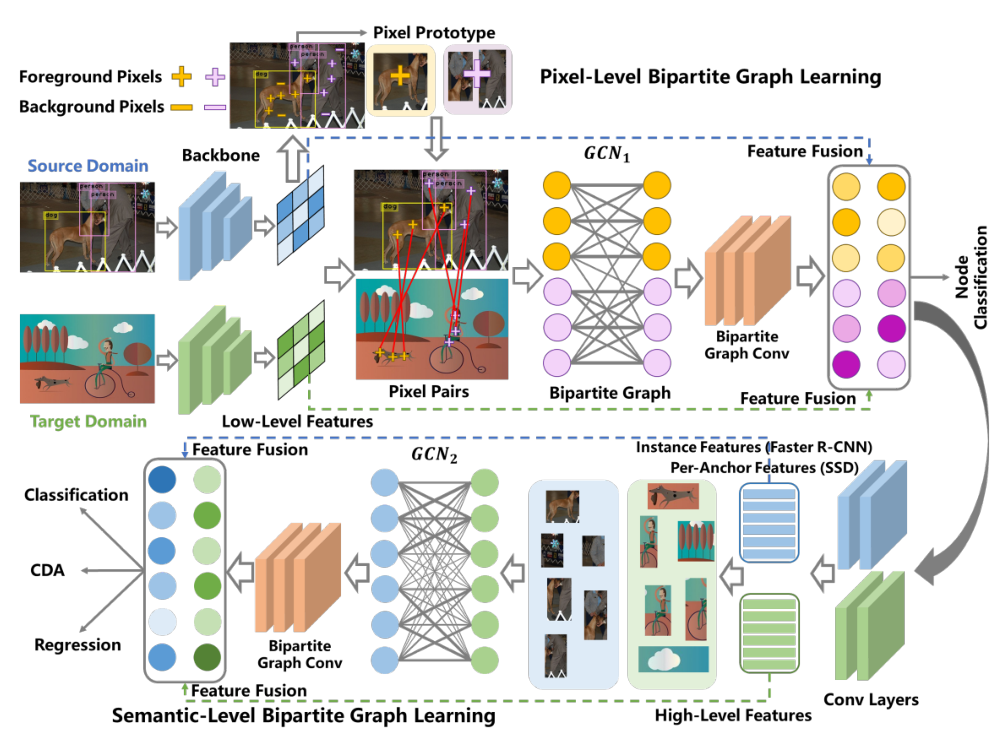
8、I3Net: Implicit Instance-Invariant Network for Adapting One-Stage Object Detectors(发表于ICCV 2021)
本文的第一作者是香港大学陈超奇博士,通信作者是信息学院信息与通信工程系黄悦副教授和香港大学俞益州教授。主要解决由于域之间的分布差异导致跨域目标检测性能下降的问题。域自适应目标检测(DAOD)通过将从标记的源域学到的知识转移到新的未标记的目标域来减轻了对大规模标注数据的依赖。最新的 DAOD 方法通常寻求域对抗训练中局部特征对齐结合特定的目标检测模型来实现细粒度特征对齐。然而,这些方法受限于适应特定类型的目标检测方法,而没有探索跨域之间的拓扑关系。本文首先将DAOD定义为一个开放集的域自适应问题,其中前景(像素或区域)被视为“已知类”,而背景(像素或区域)被视为“未知类”。为此,我们为DAOD提出了一个新的通用的视角,称为双重二部图学习(DBGL),它通过增加前景和背景之间的鉴别性来捕捉像素级和语义级的跨域交互以及建模不同语义类别之间的跨域依赖性。实验表明,所提出的DBGL与单阶段和双阶段目标检测的结合方法在标准DAOD基准上超越现有先进方法的性能。
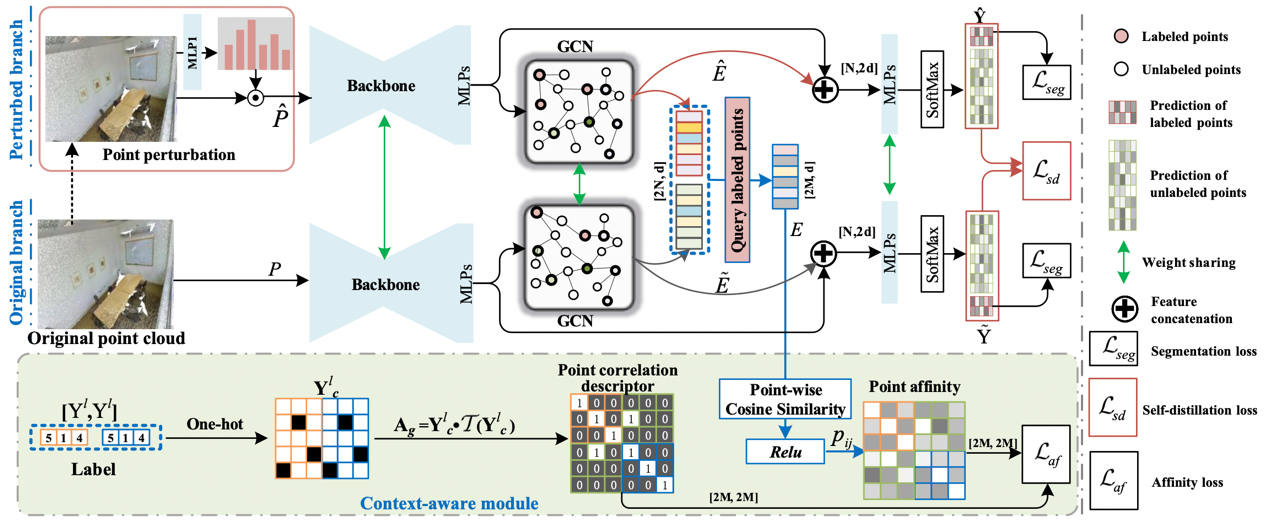
9、Perturbed Self-Distillation: Weakly Supervised Large-Scale Point Cloud Semantic Segmentation(发表于 ICCV2021)
本文的第一作者是信息学院计算机科学与技术系2018级博士生张亚超,通讯作者是信息学院计算机科学与技术系曲延云教授、华东师范大学谢源教授。针对全监督大尺度点云分割任务需要大量完全标注导致的高成本的缺陷。本文提出了一种扰动自蒸馏的弱监督大尺度点云分割方法。借助自监督学习框架,构建了扰动分支,并引入了扰动分支和原始分支之间的预测一致性限制。通过自监督学习,为无标记点引入了附加的监督信息,来约束图卷积层,从而有效地建立整个点云的图拓扑关系,从而实现标记点和未标记点之间的信息传播。除了在对点云中的点施加监督外,我们还提出了可插拔的上下文感知模块,通过标记点之间的亲和度,来约束特征关系。因此,可以进一步细化点云的图拓扑。在三个大规模数据集上的实验结果表明,与最近的弱监督方法相比,所提方法取得了显著的提升(平均 3.0%),并且所提出的弱监督方法达到了与全监督方法相媲美的结果。
10、E^2Net: Excitative-Expansile Learning for Weakly Supervised Object Localization(发表于ACM MM 2021)
本文的第一作者是信息学院人工智能系2020级博士生陈志威,通信作者是信息学院计算机科学与技术系曹刘娟副教授。针对对弱监督目标定位任务中仅定位目标最显著性部分而忽略整体的问题,论文提出了一种端到端激励扩展网络,引导模型从不同的角度去激活目标非显著性定位特征以提高定位性能,同时不影响网络的分类性能。本方法平衡了弱监督目标定位任务中的定位和分类,定位和分类精度均得到了提升。论文在多个公开数据集上进行实验,充分证明了该方法的有效性和通用性。
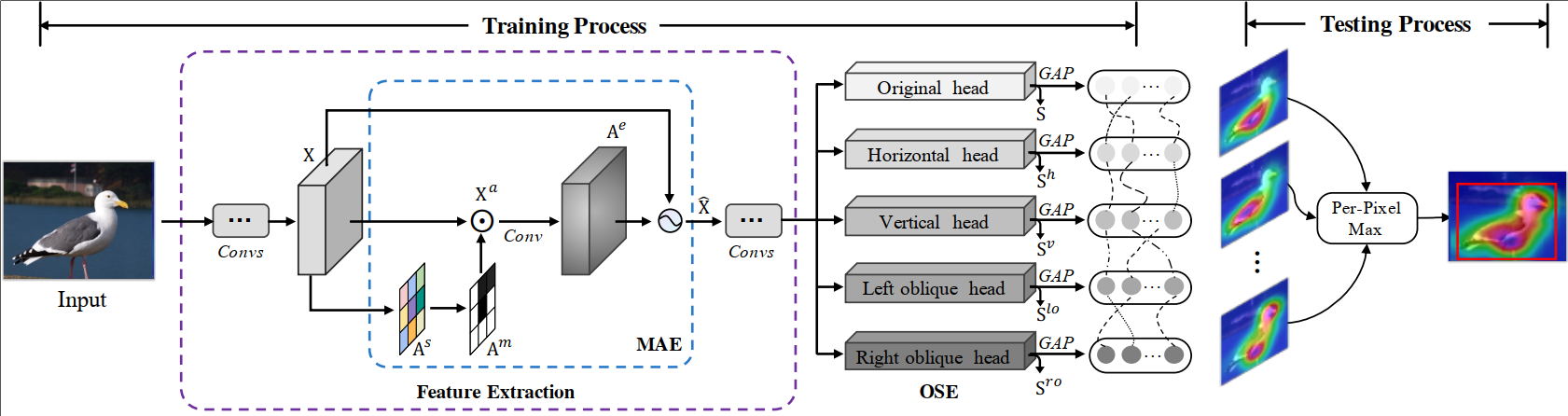
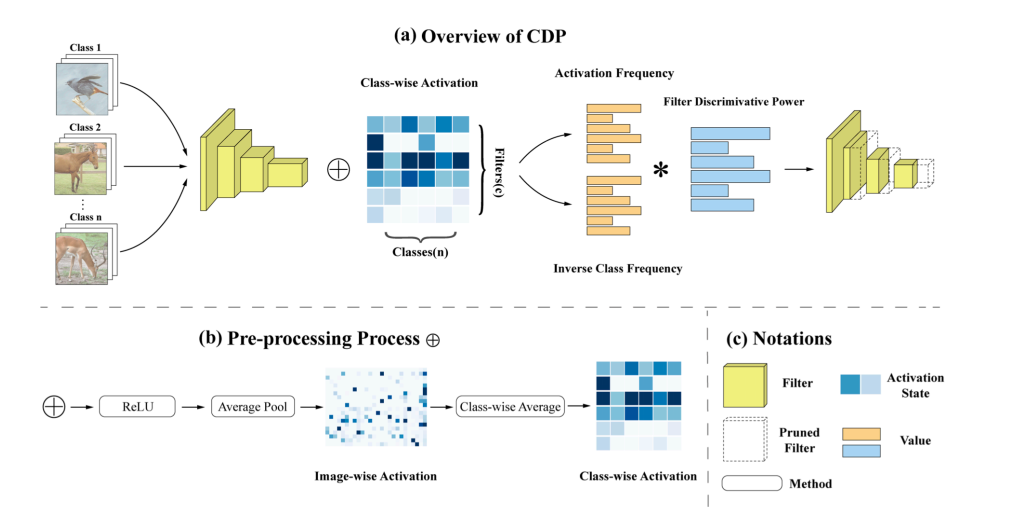
11、CDP: Towards Optimal Filter Pruning via Class-wise Discriminative Power(发表于ACM MM 2021)
本文的第一作者是信息学院人工智能系2020级硕士生许添硕,通讯作者是信息学院人工智能系晁飞副教授。论文基于传统信息检索算法TF-IDF,提出了根据滤波器类区分度的滤波器剪枝方法(CDP)。不同于传统的剪枝方法,CDP提出了一个新的剪枝理念,CDP将滤波器看做词,而每一层的特征图看做文档,从对文档的重要性来说,不仅出现次数较少的词不重要,在所有文档中频繁出现的词,比如:你、我、的等同样不具有意义。也就是说,极少激活的滤波器与面对所有类的输入都频繁激活的滤波器一样,缺乏对输入特征的区分度,因此可以被剪掉。本文在传统信息检索算法TF-IDF的基础上,针对CNN的特点进行优化,计算每个滤波器的类区分度,最后将得分低的滤波器剪掉。特别的,CDP不需要任何动态搜索过程以及迭代过程,即可在主流数据集上超越目前的SOTA方法,具有简单、高效的特点。目前前代码已经开源:https://github.com/Tianshuo-Xu/CDP-TowardsOptimal-Filter-Pruning-via-Class-wise-Discriminative-Power.git
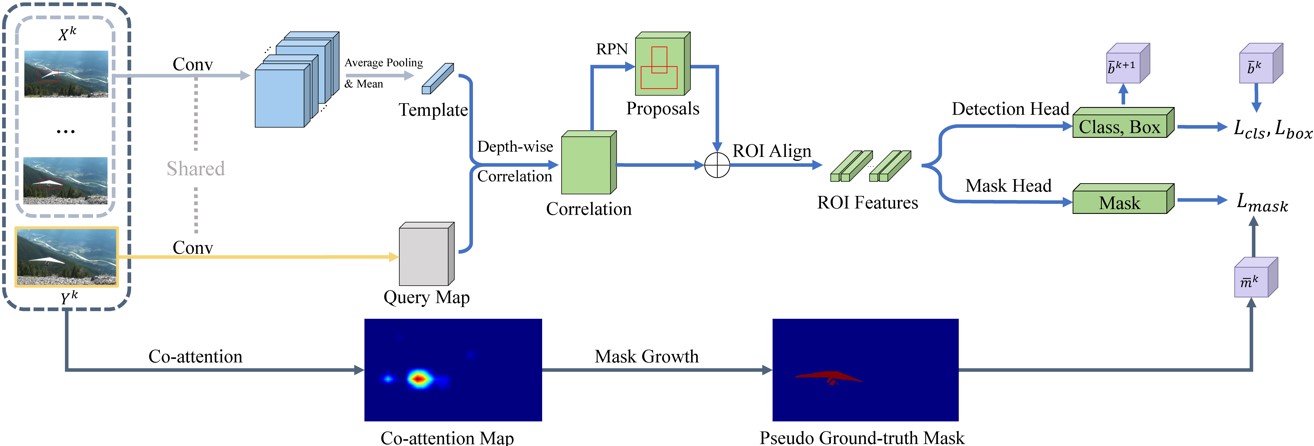
12、Towards Accurate Localization by Instance Search(发表于ACM MM 2021)
本文的第一作者是信息学院计算机科学与技术系2019级硕士生洪义耕,通讯作者是计算机科学与技术系赵万磊副教授。本文利用无监督实例检索靠前的检索结果,采用孪生网络和主成分分析方法,对实例检索前128个图像内的目标实例进行精确定位,定位效果比当前其他最好方法高11%,甚至接近采用强监督方法的定位效果。该方法还进一步应用到单样本的视觉物体识别任务上,获得了当前最好的结果。
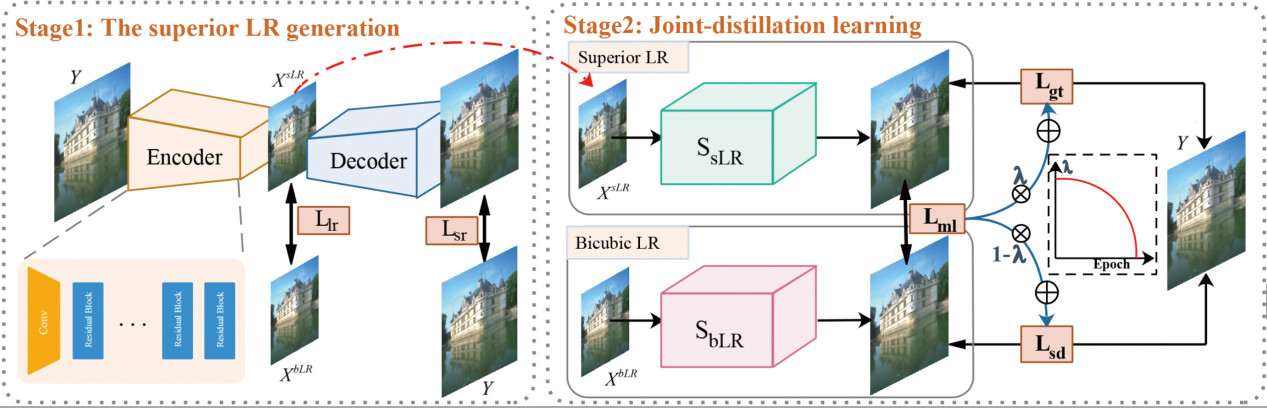
13、Boosting lightweight Single Image Super-resolution via Joint-distillation(发表于ACM MM 2021)
本文的第一作者是信息学院计算机科学与技术系2020级博士生罗小同,通讯作者是信息学院计算机科学与技术系曲延云教授。超分辨率模型存在模型复杂性高和内存占用大的问题,该论文提出了一种联合蒸馏框架,以进一步增强已有轻量级超分模型的表达能力。该框架包括同伴低分生成阶段和联合蒸馏学习阶段。同伴低分生成通过高分图像训练获得,使用该低分图作为输入的网络能以极少的花销达到与大模型相当的超分性能。联合蒸馏学习包括模型内部的自蒸馏和外部的互学习。内部自蒸馏旨在通过将知识从网络深层迁移到浅层,从而实现模型的自提升。外部互学习旨在从同伴网络中获取交互信息。此外,引入了课程学习策略和性能差距阈值,以平衡原始网络和同伴网络的收敛速度。实验结果表明,该方法在超分基准数据集提升了当前轻量级超分模型的性能,同时保持相同的模型结构和推理开销。
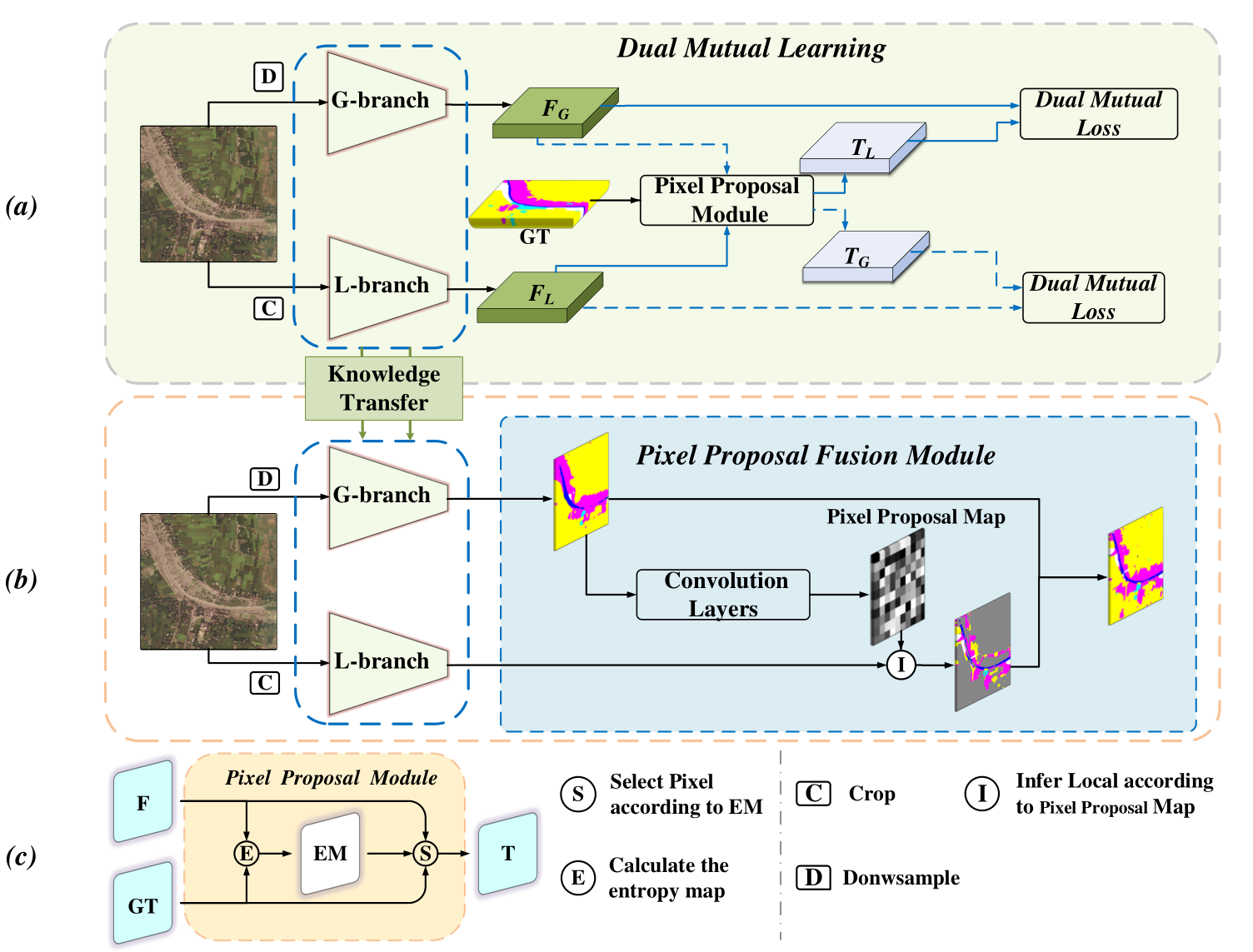
14、Faster-PPN: Towards Real-Time Semantic Segmentation with Dual Mutual Learning for Ultra-High Resolution Images(发表于ACM MM 2021)
本文的第一作者是信息学院计算机科学与技术系2019级硕士生戴必成和2020级硕士生吴楷生,通讯作者是信息学院计算机科学与技术系曲延云教授、华东师范大学谢源教授。大尺度图像语义分割的主要难点在于计算资源消耗大、分割精度低等问题。已有的大尺度语义分割方法PPN、GLnet存在执行效率低等问题,提出了一种可用于大尺度图像的实时语义分割的高效全局-局部协同的快速块推荐网络 Faster-PPN。Faster-PPN由双向互学习模块和像素提议融合模块组成,双向互学习模块从教师网络中挑选出分布合理的图像块用于全局和局部分支的互学习,在提升分支结果的同时缓解了以往互学习所带来的同质化问题,使得全局和局部分支的融合结果能得到进一步提高。相比于PPN的块推荐机制,Faster-PPN中的像素推荐融合模块可以自适应地从全局分支中挑选出像素级别的待增强特征,从而大大减少了待增强特征的数量。基于像素级的推荐网络使得Faster-PPN可以实现大尺度图像的实时语义分割。实验结果表明,该方法在3个大尺度图像数据集的精度,推理速度以及内存占用方面都达到了当前同类算法中最好的结果。
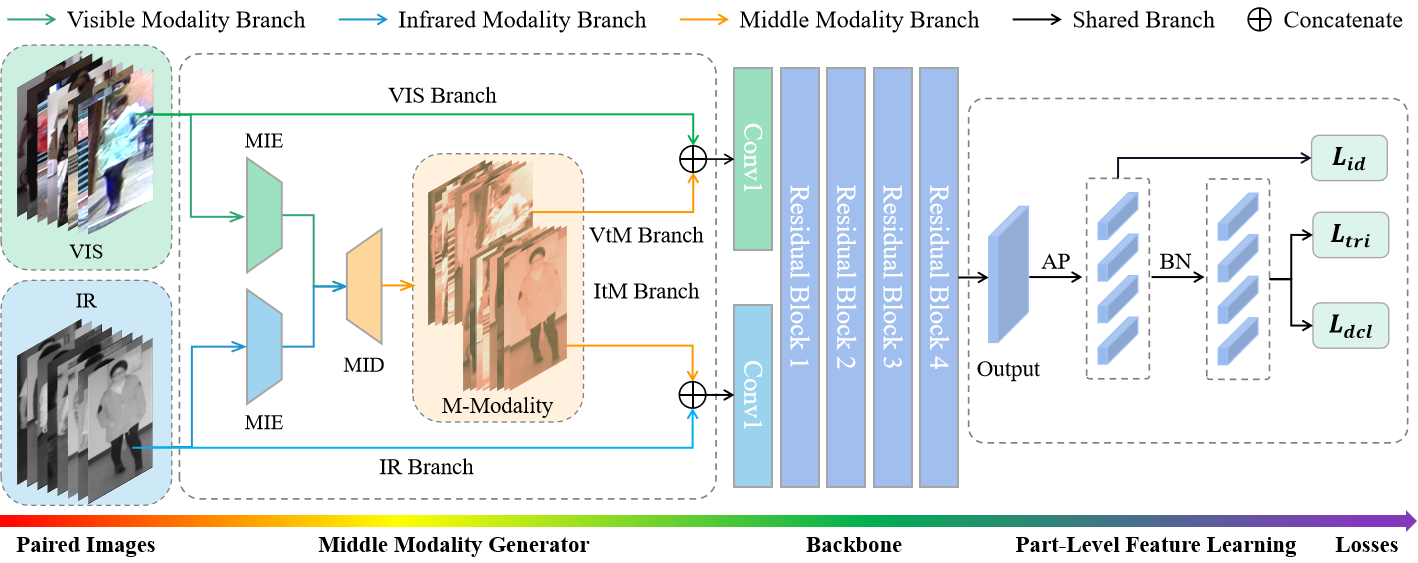
15、Towards a Unified Middle Modality Learning for Visible-Infrared Person Re-Identification(发表于ACM MM 2021)
本文的第一作者是信息学院计算机科学与技术系2020级博士生张玉康,通讯作者是信息学院计算机科学与技术系王菡子教授。论文提出了一种基于统一中间模态网络的跨模态行人重识别方法(MMN),包括中间模态生成器和分布差异损失,中间模态生成器首先将两个模态的图像分别输入到两个参数不共享的通道层面的编码器进行编码,接下来将其输入到一个共享的解码器中生成统一的中间模态图像,中间模态图像与原始图像一起输入到网络中用于辅助原始图像学习有效的特征表征。为了进一步的降低模态差异、拉近两种中间模态图像之间的距离,该论文提出了一个分布差异损失,有效的改善了模型的性能。实验结果表明,该方法在2个常用的跨模态行人重识别数据集上都达到了最好的性能。就rank1而言,超越了现有方法10%以上。
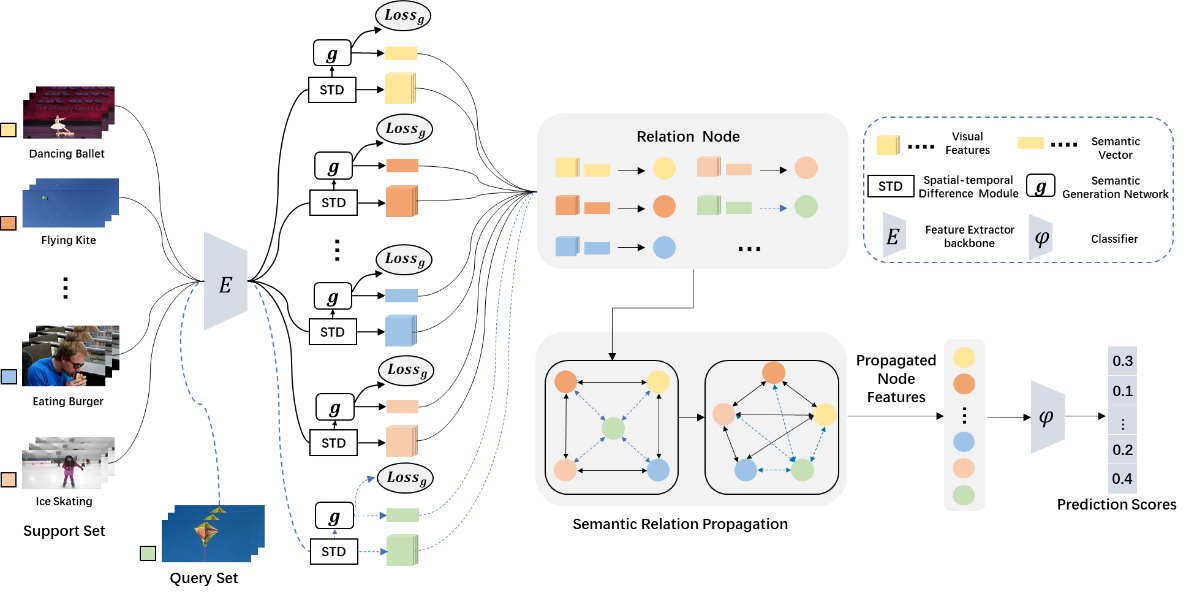
16、Semantic-Guided Relation Propagation Network for Few-shot Action Recognition(发表于ACM MM 2021)
本文的第一作者是信息学院计算机科学与技术系2019级博士生王晓和2019级硕士生叶伟荣,通讯作者是信息学院计算机科学与技术系王菡子教授。论文利用通过引入利用样本的标签信息去监督网络进行学习。当训练样本较少时,语义信息可以辅助网络学习更具有判别力的信息。然而,对于特别复杂的相似类,仅仅使用语义信息还是不能够很好的进行视频分类。考虑到视频序列里面含有丰富的时序信息,该文提出了时空差异性模块来提升对视频的视觉特征学习能力。实验结果表明,该方法在3个数据集都达到了优越的行为识别性能。
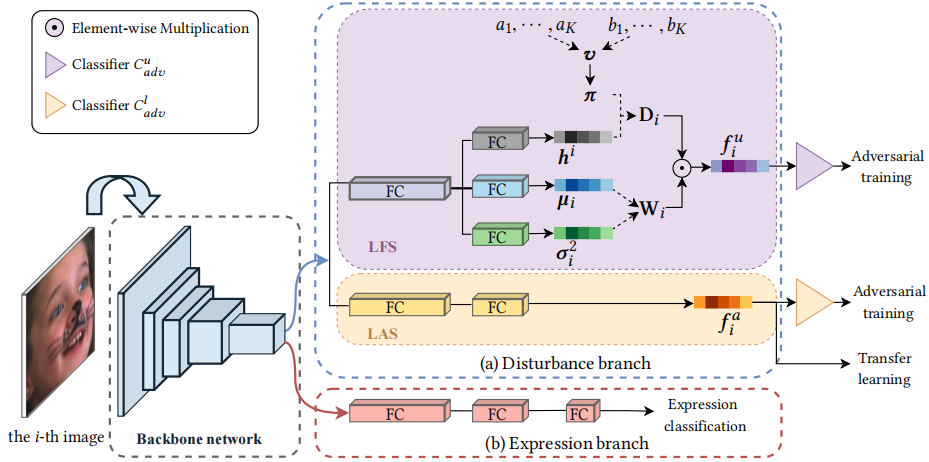
17、D3Net: Dual-Branch Disturbance Disentangling Network for Facial Expression Recognition(发表于ACM MM 2021)
本文的第一作者是信息学院计算机科学与技术系2019级硕士生莫榕云,通讯作者是信息学院计算机科学与技术系严严副教授。论文提出了一种基于多任务框架的双分支干扰分离的人脸表情识别方法(D3Net),包括表情分支和干扰分支,可以同时分离常见干扰特征和潜在干扰特征,提取更有效的表情特征。其中,干扰分支包含两个子分支。一个子分支利用其它人脸数据集的干扰标签和迁移学习的方式来训练,可以提取常见干扰特征。另一个子分支结合非参数贝叶斯先验——印度自助餐过程(IBP)先验,以无监督的方式学习潜在干扰特征。同时,该方法通过对抗训练来区分干扰特征和表情特征。最后,优化联合损失,促使表情分支更专注于提取高判别力的表情特征。实验结果表明,该方法在3个室内数据集和2个室外数据集上都达到了优越的识别性能。
ICCV作为计算机视觉领域国际顶级会议之一,由IEEE举办,被澳大利亚ICT学术会议排名和中国计算机学会等机构评为最高级别学术会议,在业内具有极高的评价。本次ICCV共计6236篇有效提交论文,其中有1617篇论文被接收,接收率为25.9%。
ACM MM是计算机学科公认的多媒体领域的国际顶级会议,被中国计算机学会列为A类会议,本次全球1942篇投稿中,542篇论文被录用,接收率为27.9%。

